2023-09-27_AnyMAL - An Efficient and Scalable Any-Modality Augmented Language Model
| 2023_Moon_AnyMAL.pdf| 2023-09-27 | Seungwhan Moon, Andrea Madotto, Zhaojiang Lin, Tushar Nagarajan, Matt Smith, Shashank Jain, Chun-Fu Yeh, Prakash Murugesan, Peyman Heidari, Yue Liu, Kavya Srinet, Babak Damavandi, Anuj Kumar | URL | arxiv | FAIR, Meta
MultiModal LLM
- multi-modal input ->text output
- 多种模态text, image, video, audio, IMU motion sensor
- Videos are encoder by video encoder!
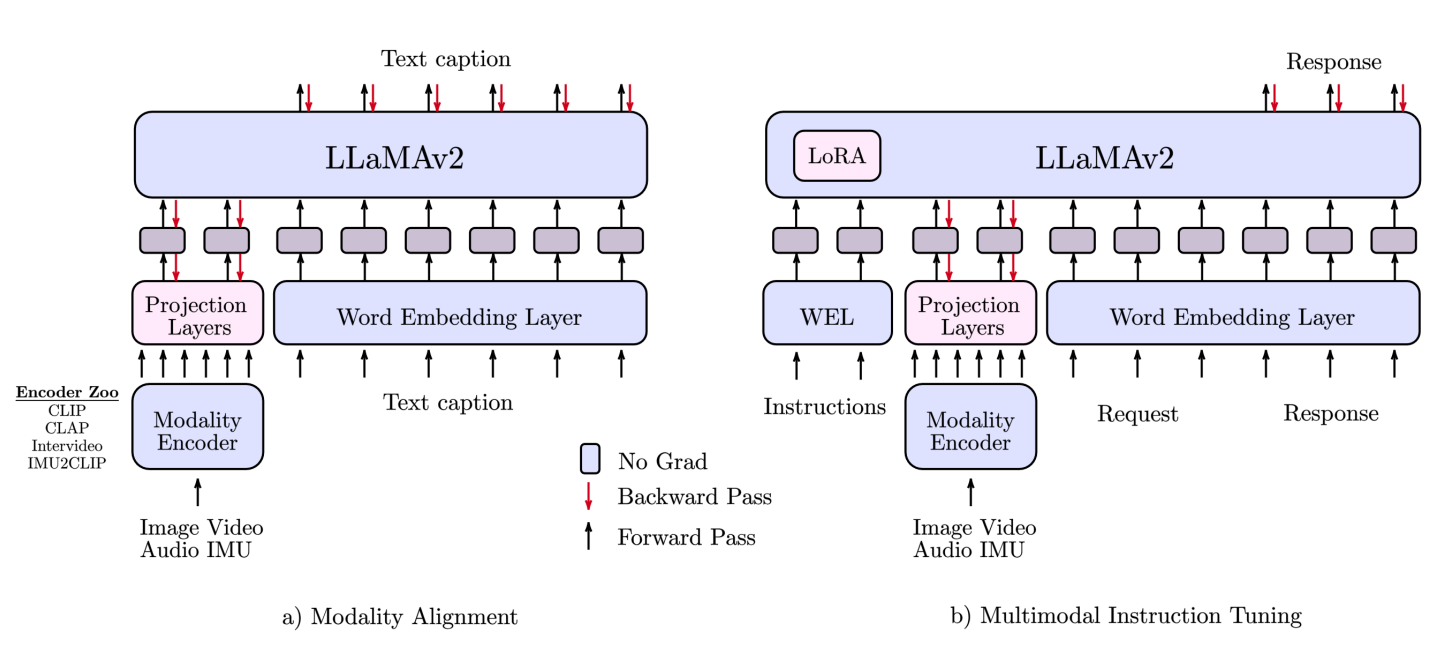
Model: 三部分
- instruction-tuned LLMs (i.e. LLaMA-2-70B-chat) ,居然用了assistant
- pre-trained modality encoders (aligned with text during pretrain, e.g. CLIP, Intervideo)
- projection layers:[Perceiver Resampler] ,project each modality into fixed size token embeddings
Training:
- Modality alignment pre-training,使用图像文本对,视频-文本对等paired data,只tune Projection layer,没有LoRA!
- multimodal instruction tuning(Supervised Finetune, SFT) with LoRA
Implementation
Chinchilla as LM,最大80B
只调LoRA和Projection Layer -> pretrain on single 80G GPU! 对frozen llm用了quantazation
Evaluation
Human Eval
Insight
传统Generative Vision-Language Model(e.g. BLIP) evaluates on downstream tasks with finetuning setting.
AnyMAL evaluates in a zero-shot setting! GOOD!
Its zero-shot ability comes from Instruction Finetuning!
Insight: treat Vision-Language Pretraining as a LLM-centric perspective, and use Instruction Finetuning, is a good new direction of doing Vision-Language Pretraining.
Pros
Model: simple, while make good use of existing LLM&Modality Encoder
New Eval Approach:Human Evaluation,更合理,但难以公平比较?
Cons
The number of token embeddings used to represent each input modality is fixed per adapter, ranging from 64 256 in this work
- 不够灵活,尤其对于Video&Audio
Question
Larger Model performs worse on COCO-Caption, Why?
instruction-tuning make gains on human eval, but when tested on VQA, it brings gain on some datasets and drops on other datasets, there maybe some problems here!
Experiment
multimodal instruction-tuning (MM-IT) dataset for finetune, also serve as benchmark
- Human: Manually collected
- Synthesize: augmented with LLaMA-2 following LLaVA
zeroshot EVAL for: captioning tasks, multimodal reasoning tasks
- Image/Audio Captioning: good Perf.
- human evaluation for multimodal reasoning on MM-IT: GOOD perf.
- VQA&Video QA: comptetitive
由于可能存在data contemination, 因此supervised-finetuned model 无法evaluate on strict zero-shot setup
Previous Work
Flamingo, BLIP1/2, etc.
Prior multimodal LLM research has concentrated on models that combine text and one other modality [3, 5], such as text and image models, or has centered on proprietary language models that are not open sourced [2, 4].
Abstract
We present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses. AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module. To further strengthen the multimodal LLM's capabilities, we fine-tune the model with a multimodal instruction set manually collected to cover diverse topics and tasks beyond simple QAs. We conduct comprehensive empirical analysis comprising both human and automatic evaluations, and demonstrate state-of-the-art performance on various multimodal tasks.